
nlp--使用spaCy进行大规模数据分析
数据结构
Vocab, Lexemes和StringStore
Vocab: 存储那些多个文档共享的数据
为了节省内存使用,spaCy将所有字符串编码为哈希值。
字符串只在StringStore中通过nlp.vocab.strings存储一次。
字符串库:双向的查询表
1 | nlp.vocab.strings.add("咖啡") |
哈希是不能逆求解的,所以使用共享词汇表。
如果该字符串从未出现过则会报错
1 | string = nlp.vocab.strings[7962530705879205333] |
共享词汇表和字符串库
在nlp.vocab.strings中查找字符串和哈希值
1 | #doc也会暴露出词汇表和字符串 |
Lexemes: 词汇表中的元素
Lexeme 是词汇表中和语境无关的元素。
在词汇表中查询一个字符串或者一个哈希ID就会获得一个lexeme。
Lexeme可以暴露出一些属性,就像词符一样。
它们代表着一个词的和语境无关的信息,比如文本本身,或者是这个词是否包含了英文字母。
Lexeme中没有词性标注、依存关系或者实体标签这些和语境关联的信息
Doc、Span和Token
Doc文档实例
1 | # 创建一个nlp实例 |
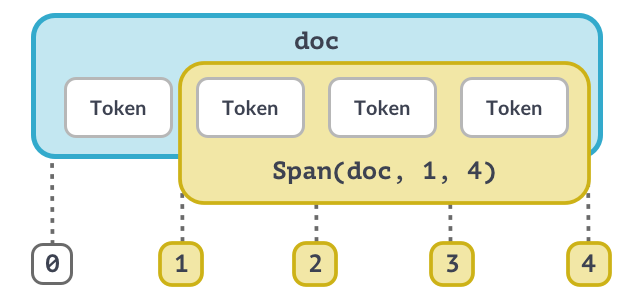
Span跨度实例(1)
一个Span是doc的一段包含了一个或更多的词符的截取。
Span类有最少三个参数:对应的doc以及span本身起始和终止的索引。
注意终止索引代表的词符是不包含在这个span里面的!
Span跨度实例(2)
要手动创建一个Span,我们还需要导入spacy.tokens中的类,
然后用doc、span的初始和终止索引以及一个可选的标签参数来初始化它。
doc.ents是可写的,所以我们可以用一个span列表覆盖它来手动添加一些实体。
1 | # 导入Doc和Span类 |
最佳实践
Doc和Span是非常强大的类,可以存储词语和句子的参考资料和关系。
不到最后就不要把结果转换成字符串
尽可能使用词符属性,比如用token.i来表示词符的索引
别忘了传入共享词汇表vocab
Top:
1 | 在开始之前我们先来看一些小技巧: |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Jacker-zzk's Blog!





